W jednym z wpisów w słowniczku wyjaśniamy czym dokładnie są analizy korelacji. Myślę, że nawet bez zaglądania do naszego słowniczka statystycznego większość z Was wie na czym one polegają, jak się je liczy w pakiecie SPSS oraz jak interpretuje się ich rezultaty. Analiza korelacji jest jedną z najpopularniejszych analiz statystycznych. Nie bez przyczyny. Wylicza się ją bardzo łatwo a jej wyniki są bardzo przystępne w odbiorze. Nie trudno zrozumieć rezultaty z niej płynące i jednocześnie łatwo je odnieść do teorii, na której opierają się nasze badania. Prawdopodobnie w większości badań z zakresu nauk społecznych wyliczano przynajmniej raz choćby jeden z najbardziej popularnych współczynników korelacji, z których korzysta 99% badaczy – r Pearsona, rho Spearmana lub tau-b Kendalla. Nawet jeśli nie zostało to opisane w artykule naukowym czy też pracy dyplomowej to zapewne jakiś badacz choćby z czystej ciekawości sprawdził czy mierzone zmienne korelują ze sobą. Nawet gdy nie zakładały tego jego hipotezy.
Czasami pomimo tego, że analizy statystyczne w postaci analizy korelacji są stosunkowo mało skomplikowane to potrafią przysporzyć badaczom nie lada problemów interpretacyjnych. Przyczyn może być wiele, ale w tym wpisie zajmiemy się tylko sytuacją, w której raz wykonujemy analizy korelacji u ogółu badanych osób, a innym razem te same zmienne korelujemy ze sobą w podziale na dwie grupy (na przykład oddzielnie w grupie kobiet i mężczyzn).
Analiza korelacji. Krótkie przypomnienie
Jak zapewne większość z Was wie, analizy korelacji wykonuje się w celu zbadania związku liniowego między dwiema zmiennymi. Zmienne te muszą być mierzone na skali porządkowej lub ilościowej. Jeśli do czynienia mamy z dwiema zmiennymi ilościowymi o odpowiednich rozkładach to wyliczamy współczynnik korelacji r Pearsona. W przeciwnym wypadku (np. bardzo silnie skośne rozkłady, obecność wielu obserwacji odstających lub zmienne o charakterze porządkowym) wyliczamy najczęściej współczynnik rho Spearmana lub tau-b Kendalla. Dziś ograniczymy się tylko do zmiennych ilościowych, które spełniają wszelkie założenia wymagane do policzenia współczynnika r Pearsona. Inne współczynniki nas nie interesują.

Powyższy rysunek prezentuje 3 różne wykresy rozrzutu będące ilustracją współwystępowania dwóch zmiennych ilościowych czyli korelacji między nimi. Rysunek A to ilustracja korelacji dodatniej. Niskie wyniki jednej zmiennej “idą w parze” z niskimi wynikami drugiej zmienne. Im wyższe wyniki uzyskuje się dla zmiennej nr 1 tym wyższe też wyniki obserwuje się w przypadku zmiennej nr 2. To jest właśnie korelacja dodatnia czyli pozytywny związek między zmiennymi. Gdy jedna zmienna rośnie to druga też rośnie lub gdy jedna maleje to druga też maleje. Wykres rozrzutu B ilustruje związek negatywny między dwiema zmiennymi. Im większe wyniki obserwuje się dla zmiennej nr 1 tym mniejsza dla zmiennej nr 2. Tym samym można też powiedzieć, że im niższe wyniki uzyskują badani w zakresie zmiennej nr 1 tym wyższe uzyskują wyniki w zakresie mierzonej zmiennej nr 2. Jest to korelacja negatywna, która polega na tym, że wartości zmieniają się przeciwstawnie do siebie. Jedna zmienna rośnie, a druga maleje lub gdy jedna maleje to druga rośnie. Ostatni wykres rozrzutu oznaczony literą C to ilustracja braku korelacji między zmiennymi. Widzimy na nim nieregularną chmurę punktów. Związek liniowy między zmiennymi nie występuje. Nic prostszego, prawda? Korelacja może występować albo nie. Jeśli występuje to może być ona dodatnia lub ujemna. To wszystko.
Analizy korelacji w podziale na grupy, czyli doprecyzowanie wyników analiz statystycznych
Bardzo często po wykonaniu analizy korelacji w całej grupie chcemy sprawdzić też czy obserwowany związek jest taki sam gdy przetestujemy go w podgrupach. Zmienną demograficzną, która różnicuje niemal wszystko co obserwujemy w naturze jest płeć. Dlatego też w większości przypadków zalecamy przeprowadzenie pewnych analiz oddzielnie w grupie kobiet i oddzielnie w grupie mężczyzn.
Analiza korelacji istotna statystycznie – analiza korelacji nieistotna statystycznie. O co tutaj chodzi?
Wyobraź sobie, że korelujesz ze sobą ocenę relacji z rodziną badanych osób i ich ogólną jakość życia. Zakładasz, że im lepsze są relacje z rodziną tym wyższa jest ogólna jakość życia badanych osób. Spodziewasz się pozytywnej korelacji między zmiennymi. Tym samym im gorsze będą relacje z rodziną tym zapewne jakość życia też będzie niższa. Analiza statystyczna przeprowadzona. Okazuje się, że zmienne korelują ze sobą i faktycznie związek, który obserwujemy jest dodatni. Oto wykres rozrzutu, który go ilustruje.
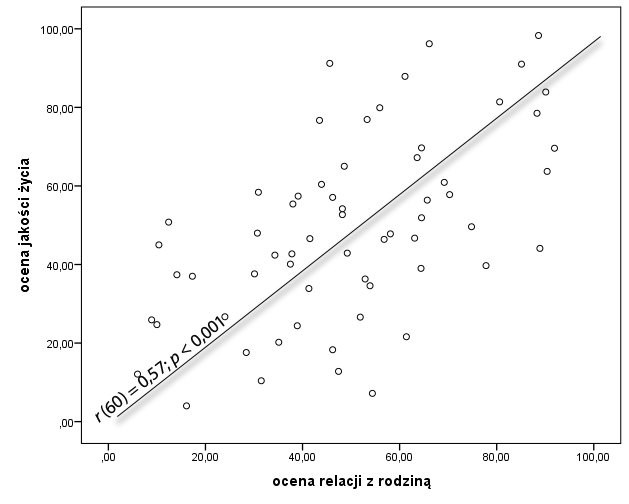
Między dwiema analizowanymi zmiennymi zachodzi istotny statystycznie związek o stosunkowo dużej sile. Pozytywny charakter tej relacji oznacza, że wraz ze wzrostem jednej zmiennej obserwuje się na wzrost wyników dla drugiej zmiennej.
Wyobraź sobie, że korelujesz ze sobą ocenę relacji z rodziną badanych osób i ich ogólną jakość życia. Zakładasz, że im lepsze są relacje z rodziną tym wyższa jest ogólna jakość życia badanych osób. Spodziewasz się pozytywnej korelacji między zmiennymi. Tym samym im gorsze będą relacje z rodziną tym zapewne jakość życia też będzie niższa. Analiza statystyczna przeprowadzona. Okazuje się, że zmienne korelują ze sobą i faktycznie związek, który obserwujemy jest dodatni. Oto wykres rozrzutu, który go ilustruje. Poniżej znajduje się też tabela z pakietu SPSS, która prezentuje uzyskane wyniki.

Jako, że jesteś bardzo dociekliwym badaczem, dzielisz bazę danych na podzbiory względem zmiennej “płeć”. Tym samym wszystkie dalsze analizy statystyczne wykonujesz oddzielnie w grupie kobiet i oddzielnie w grupie mężczyzn. Ponownie liczysz współczynnik korelacji r Pearsona i oto wyniki, które uzyskujesz.
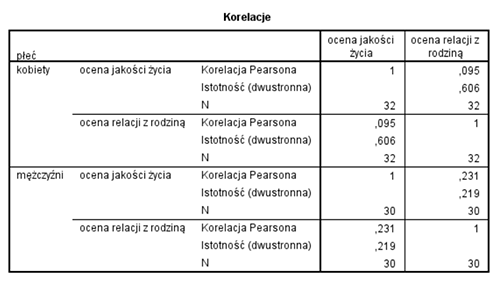
Cóż się okazuje? Uzyskane rezultaty pokazują, że związek między jakością relacji z rodziną a jakością życia nie występuje ani u kobiet ani u mężczyzn. Większość młodych badaczy, których doświadczenie w zakresie analizy statystycznej to ok 30 lub maks. 60 godzin kursu ze statystyki pyta “jak to możliwe”. Przecież poprzednia analiza (dla wszystkich badanych łącznie) mówi o tym, że związek występuje. Skoro występuje u wszystkich badanych łącznie to powinien występować także oddzielnie w grupie kobiet i oddzielnie w grupie mężczyzn, prawda? Ewentualnie w jednej grupie będzie on słabszy, a w drugiej będzie silniejszy. No dobra! Ewentualnie w jednej grupie ten związek będzie występował, a w drugiej nie. W jaki sposób korelacja, która występuje w całej badanej grupie nagle przestaje być istotna statystycznie gdy tą samą analizę statystyczną przeprowadzimy oddzielnie w grupie kobiet i mężczyzn? Przecież te obie grupy “budują” naszą całą bazę danych. Z takimi pytaniami spotykamy się bardzo często. Dlatego powstał ten wpis. Spójrz na poniższy wykres.
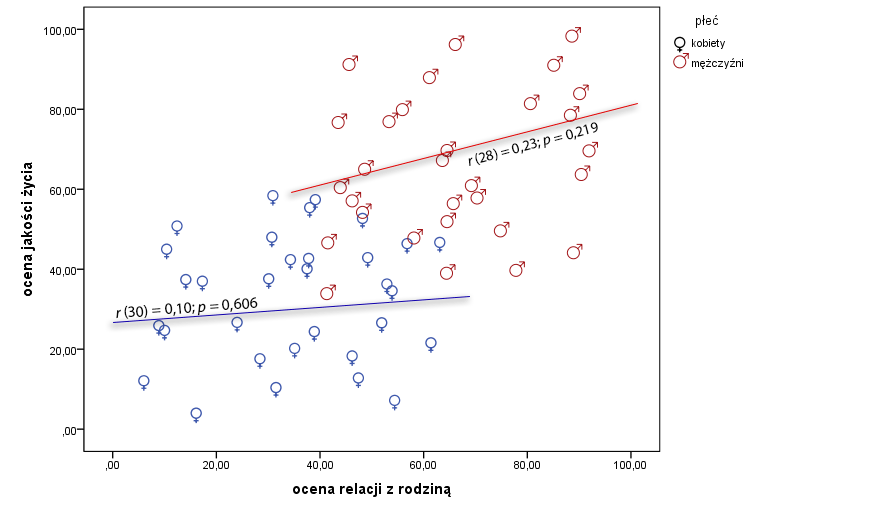
Powyższy rysunek to ten sam wykres co poprzedni, ale poprosiliśmy SPSSa żeby w inny sposób oznaczył punkty w grupie kobiet, a inaczej punkty w grupie mężczyzn. Zauważ, że oddzielnie w jednym jak i drugim przypadku mamy do czynienia z nieregularną chmurą punktów. Tak, te dwie chmury w połączeniu wskazują na dodatni związek między analizowanymi zmiennymi (analiza korelacji dla wszystkich łącznie bez podziału na płeć). Gdy jednak analizujemy współwystępowanie obu zmiennych oddzielnie w grupie kobiet i oddzielnie w grupie mężczyzn to widać, że punkty w “niebieskiej grupie” jak i punkty w “czerwonej grupie” są ułożone tak, że nie widać żadnego, dobrze znanego nam wzorca wskazującego na pozytywny lub negatywny związek między zmiennymi. Odpowiedź na wcześniejsze pytanie “jak to możliwe” to “właśnie tak jak pokazuje to powyższy rysunek”. Jeśli w swoim badaniu uzyskasz takie właśnie wyniki to nie myśl, że został przez Ciebie popełniony błąd. To normalna, choć stosunkowo rzadko występująca sytuacja.
Analizy statystyczne bez tajemnic, czyli dlaczego tak się dzieje i jak to zinterpretować?
Powody opisanego stanu rzeczy mogą być przynajmniej dwa. Występować mogą one jednocześnie jak i osobno.
Powód 1: Spadek mocy testu po podziale bazy danych na dwie mniejsze grupy.
Tak właśnie. Moc testu statystycznego czyli (w wielkim uproszczeniu) skłonność testu do wskazania wyniku istotnego statystycznie jest w dużej części uzależniona od liczby badanych osób. Korelacja wynosząca r = 0,24 może być nieistotna statystycznie w grupie 40 badanych osób, a taki sam wynik współczynnika r Pearsona będzie istotny statystycznie gdy przebadany 120 osób. Zauważ, że na początku (u ogółu badanych osób) analizy wykonywaliśmy na 62 uczestnikach badania. Dzieląc bazę danych na dwie mniejsze grupy (32 kobiety i 30 mężczyzn) spadła moc testu i tym samym bardziej prawdopodobne jest zaobserwowanie wyniku nieistotnego statystycznie w grupie kobiet i grupie mężczyzn gdy analizujemy je oddzielnie. Analizy korelacji, podobnie jak wszystkie inne, są w większości bardziej skłonne do pokazywania wyników istotnych statystycznie gdy przebadaliśmy bardzo dużo osób.
Powód 2: Różnice między grupami w zakresie mierzonych zmiennych.
Drugą przyczyną lub dokładniej, sytuacją sprzyjającą opisywanemu zjawisku, są różnice pod względem średnich wyników obu zmiennych ilościowych między dwiema grupami, które “rozbiły” naszą bazę danych. Po prostu kobiety różnią się od mężczyzn zarówno w zakresie oceny swoich relacji z rodziną jak i ogólnej jakości życia. Linie narysowane dla ułatwienia ilustrują to bardzo dobrze. Zauważ, że średni wynik mężczyzn w przypadku oceny relacji z rodziną jest niemal dwa razy większy od średniego wyniku obserwowanego w grupie kobiet. Podobne zróżnicowanie dostrzec można także w ogólnej ocenie jakości życia. Wykonany test t Studenta dla prób niezależnych potwierdza, że różnice te są istotne statystycznie na poziomie p < 0,001.
UWAGA UWAGA: różnice w średnich między grupami, które dzielą naszą bazę na podzbiory, to po prostu coś co sprzyja opisywanemu zjawisku. Możliwe, że średnie będą się różniły, a i tak korelacje będą istotne w obu podgrupach.
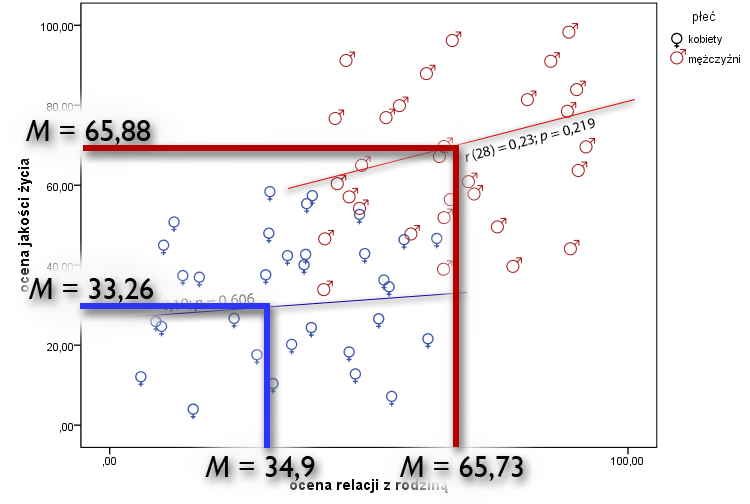
Pamiętaj, że Twoim celem jako badacza jest wyjaśnienie, czym spowodowana jest zmienność np. w zakresie ogólnej jakości życia. Wiesz już, że jakość życia współwystępuje z jakością relacji z rodziną. Okazuje się też jednak, że ta jakość życia zależy od płci i to tak silnie, że związek tej zmiennej (ogólnej jakości życia) z jakością relacji z rodziną przestaje być związkiem istotnym. Można przekonać się o tym wykonując np. analizę regresji liniowej.
Analizy korelacji w podziale na dwie grupy, cz. I – podsumowanie
Niejedno z Was zada sobie w tym miejscu pytanie “jak zinterpretować ten wynik”? Wiemy już co wyszło z analiz. Wiemy też dlaczego mogliśmy uzyskać takie wyniki, i że to nic dziwnego. Jaka jest jednak ostateczna odpowiedź i co napisać w dyskusji wyników? Korelacja między jakością relacji z rodziną a ogólną jakością życia występuje czy nie? Odpowiedź brzmi: tak, występuje, ale gdy nie bierzemy pod uwagę płci badanych osób. Faktycznie gdy nie posiadamy informacji o płci to możemy uznać, że zachodzi związek między jakością życia a jakością relacji z rodziną. Żyjemy jednak na planecie Ziemia i każda badana osoba ma przypisaną pewną płeć, którą znamy. W dyskusji wyników powinniśmy tym samym napisać dosłownie, że kontrolując zmienność badanych w zakresie płci związek między jakością życia a jakością relacji z rodzicami staje się nieistotny statystycznie. Dodatkowo należy wspomnieć o tym, że kobiety znacznie różniły się od mężczyzn zarówno w zakresie ogólnej oceny jakości swojego życia jak i oceny swoich relacji z rodziną.
Tutaj znajdziesz drugą część artykułu – CZĘŚĆ 2

