Słownik
Średnia
Średnia to jedna z podstawowych miar statystycznych, służąca do określania wartości centralnej zbioru danych. Średnią zwykle raportujemy pod oznaczeniem litery M od angielskiego słowa mean. Może być rozumiana na kilka sposobów:
1. Średnia arytmetyczna: To najpopularniejsza forma, gdzie sumuje się wszystkie wartości i dzieli przez liczbę elementów w zbiorze.
Załóżmy, że mamy zbiór liczb: 5, 10, 15, 20, 25. Aby obliczyć średnią arytmetyczną tych liczb, dodajemy je wszystkie razem i dzielimy przez liczbę elementów:
(5 + 10 + 15 + 20 + 25) / 5 = 75 / 5 = 15
2. Średnia ważona: Każda wartość ma przypisaną wagę, a średnia jest obliczana przez uwzględnienie tych wag. Przeważnie stosowana systemie oceniania do nadawania wyższej wartości np. różnym zadaniom domowym studenta.
Weźmy ten sam zbiór liczb, ale tym razem nadajmy im wagi. Załóżmy, że wagi to odpowiednio 1, 2, 3, 4, 5 dla liczb 5, 10, 15, 20, 25. Obliczmy średnią ważoną:
(5*1)+(10*2)+(15*3)+(20*4)+(25*5) / (1 + 2 +3 + 4 +5) = 205 / 15 = 13,6
3. Średnia harmoniczna: Ta forma jest stosowana w przypadkach, gdy istotne jest uwzględnienie relacji między liczbami, zwłaszcza w dziedzinach takich jak finanse i statystyka opisowa. Przykładowo:
Weźmy pod uwagę te same liczby jak w przypadku średniej arytmetycznej, ale potraktujmy je jako stopy procentowe zwrotu z inwestycji w pięciu okresach czasu równe 5%, 10%, 15%, 20%, 25%. Obliczmy zatem średnią harmoniczną:
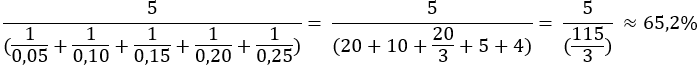
Zastosowanie średniej ułatwia porównywanie różnych zbiorów danych oraz analizę trendów i wzorców. W przypadku badań naukowych, powszechnie dokonuje się obliczeń średniej arytmetycznej, w kilku podstawowych celach:
- charakterystyka badanej próby, np. średnia arytmetyczna wieku, w przypadku badania prowadzonego na ludziach
- analiza podstawowych statystyk opisowych, w której oprócz średniej oblicza się często odchylenie standardowe, medianę, skośność i kurtozę
- jako element wnioskowania statystycznego w oparciu o testy statystyczne porównujące średnie (np. test t Studenta lub analiza wariancji); w tym przypadku oblicza się średnie wartości zmiennej zależnej w podziale na różne grupy wyróżnione ze względu na zmienną niezależną
Średnia może być podatna na wpływ wartości skrajnych (outlierów), co może zakłócić jej interpretację. Na rysunku 1 zaprezentowano symulowane dane, które prezentowały roczne zarobki deklarowane w próbce 1000 osób oraz zobrazowano jak wygląda średnia i mediana przy uwzględnieniu wartości skrajnych.
Rysunek 1
Przykład oddziaływania wartości skrajnej na średnią i medianę w badanej próbce

Jak widać na rysunku 1, rozkład po prawej stronie (błękitny) jest rozkładem przypominającym rozkład normalny, gdzie średnia (M = 35,16 tys. zł) i mediana (Mdn = 35,09 tys. zł) pokrywają się, a obrazująca je przerywana linia przecina idealnie środek uzyskanych wartości. W przypadku analizy rozkładu danych po prawej (zielony), mamy typowy rozkład zarobków w którym pojawiają się wartości skrajne (osoby lepiej zarabiające). Dodanie obserwacji odstających spowodowało przesunięcie średniej z 35 tysięcy do prawie 46 tysięcy zł (znikąd zarabiamy o 11 tysięcy więcej jako przeciętny pracownik!), natomiast mediana zareagowała w mniejszym stopniu (z 35,09 tys. zł do 36,27 tys. zł), która lepiej obrazuje że podwyżki przeciętnej płacy jednak nie ma, a przynajmniej nie jest tak wielka.
Zwykle średnią wykorzystujemy np. w teście t Studenta, jednak gdy zaobserwujemy wartości skrajne których nie możemy usunąć, alternatywą jest właśnie mediana, która jest naszą statystyką centralnej tendencji porównywanych grup w testach nieparametrycznych.
Kontrola naszej próby ma istotne znaczenie w występowaniu obserwacji skrajnych, warto starać się dobierać próby w sposób kwotowy, aby dobierać reprezentatywne próbki osób gorzej lub lepiej zarabiających, odzwierciedlających ich odsetek w populacji. Dobrze wyważone próbki obserwacji pozwolą nam względnie dobrze uniknąć problemu wartości odstających, dlatego zawsze warto przyjrzeć się wstępnym rozkładom zmiennych poprzez zastosowanie statystyk opisowych.
Podsumowując średnia jest kluczowym narzędziem w statystyce, ponieważ pozwala na uogólnienie danych poprzez zredukowanie ich do jednej liczby, jednak jest ona podatna na wartości odstające. Dlatego też, oprócz średniej w analizie danych zwykle stosuje się także inne statystyki opisowe, takie jak mediana czy odchylenie standardowe, aby uzyskać pełniejszy obraz rozkładu wartości w zbiorze.


