W ostatnim wpisie pokazaliśmy Wam, że czasami analizy statystyczne ujawniają wyniki, które na pierwszy rzut oka wydają nam się błędne. SPSS raczej się nie myli więc ewentualny błąd może leżeć po naszej stronie. Wiesz już jednak, że rezultaty, które mogą wydawać się błędne są w zupełności prawdziwe i uzyskane w toku poprawnie wykonanych testów statystycznych. Trzeba tylko wiedzieć co się dzieje z danymi po dokonaniu pewnych operacji i dlaczego właśnie to może się z nimi dziać. Wtedy okiełznasz dane i nawet najbardziej nielogiczne rezultaty będą pod Twoją pełną kontrolą dzięki czemu poddasz je właściwej interpretacji i wyciągniesz poprawne wnioski. Pamiętaj, że pozbawiony logiki nie jest wynik testu, lecz Twoja jego interpretacja. Niniejszy wpis ma za zadanie ukazanie innej często spotykanej sytuacji w przypadku wykonywania analizy korelacji najpierw ogółem u wszystkich badanych łącznie, a następnie w podziale na dwie lub więcej grup.
Analiza korelacji nieistotna statystycznie – analiza korelacji istotna statystycznie. O co tutaj chodzi?
Ostatni wpis dotyczył sytuacji odwrotnej niż powyższy tytuł tego akapitu. Pokazaliśmy Wam, że czasami najpierw korelacja w całej badanej próbie występuje, a gdy analizy korelacji wykonamy w podziale na jakieś dwie grupy (np. oddzielnie u kobiet i mężczyzn) to związek przestaje być istotny statystycznie. Możliwe też jest zaobserwowanie odwrotnego zjawiska, zgodne z tytułem tego akapitu. Gdy wykonujemy analizę statystyczną dla ogółu badanych osób to współczynnik korelacji jest nieistotny statystycznie. Gdy dokonamy podziału na jakieś dwie grupy (lub więcej grup) to okazuje się, że korelacja między zmiennymi zachodzi … nawet w obu grupach jednocześnie! W takich przypadkach studenci również często pytają: Jak to możliwe? Koreluję ze sobą dwie zmienne. Związku nie ma. Nagle dzielimy bazę na dwie podgrupy, które “ładują” całą naszą bazę danych i okazuje się, że jednak w jednej i drugiej grupie związek jest istotny statystycznie. To dlaczego w obu grupach łącznie nie był? Czary? Wcale nie. Już pokazuję jak to możliwe.
Wyobraźmy sobie, że chcemy sprawdzić czy zachodzi istotny statystycznie związek między zarobkami (miesięczny dochód netto) a optymizmem (skala ogólnego optymizmu życiowego). Obie zmienne są mierzone na skali ilościowej i załóżmy, że mają niemalże idealny rozkład normalny. Oto wyniki przeprowadzonego testu.
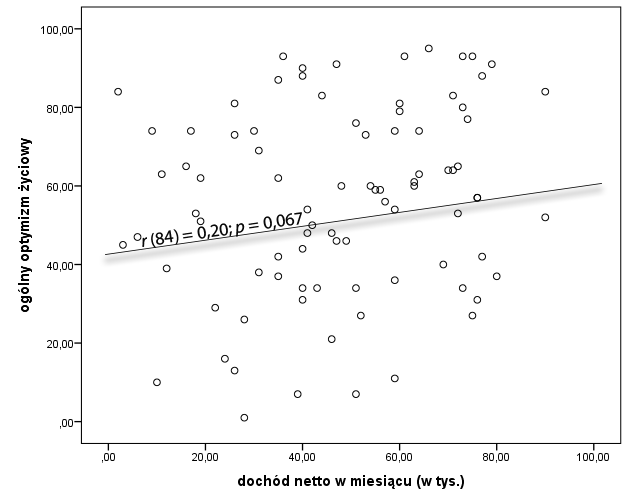
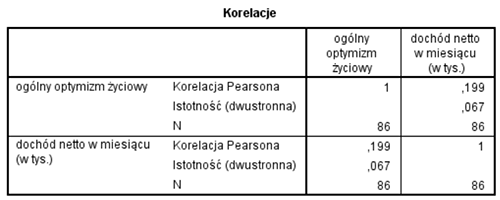
Współczynnik r Pearsona wynosi tylko 0,2 a istotność statystyczna czyli wartość p wynosi 0,067. Jest to wynik istotności bardzo bliski poziomu 0,05 i może być uznany za rezultat istotny na tak zwanym poziomie tendencji statystycznej, ale uznajmy, że jest on po prostu nieistotny, i że pojęcia “tendencja statystyczna” nie znamy lub jesteśmy przeciwnikami jego stosowania (a jest ich wielu :). Uzyskany rezultat wskazuje zatem na to, że brak jest związku liniowego między zarobkami a nasileniem optymizmu. Brak jest tym samym podstaw do stwierdzenia, że im więcej zarabiamy, tym bardziej optymistycznie jesteśmy nastawieni do świata. Widać to nawet na wykresie rozrzutu. Chmura punktów jest raczej nieregularna i naprawdę trudno dopatrzeć się tutaj jakiegoś liniowego związku. Jako badacze, którzy zakładali, że taki związek będzie dostrzegalny zapewne jesteśmy bardzo smutni i zrezygnowani.
Podział na podzbiory. Czy na pewno zarobki nie korelują z optymizmem?
Nawet na poziomie studiów licencjackich, a tym bardziej magisterskich i doktoranckich, przeprowadzając badanie i analizując zebrane wyniki myślcie o sobie jako podróżnikach, odkrywcach lub poszukiwaczach. Myślisz, że prawdziwemu odkrywcy wystarczy odpowiedź “tu nic nie ma”? Zapewniam Cię, że nie. Jeśli masz zasoby i umiejętności to szukaj dalej. Wiesz zapewne, że wiele odkryć istotnych dla całej ludzkości było wynikiem przypadku lub pomyłki.
Okazuje się, ze w bazie danych mieliśmy jeszcze kilka innych zmiennych. Jedną z nich, która przykuła naszą uwagę, była informacja o tym, czy badany respondent posiada psa czy też nie. Bez chwili wahania dzielimy bazę danych na dwie grupy i analizę korelacji wykonujemy oddzielnie u osób, które posiadają psa i oddzielnie u tych, które psa nie posiadają. Oto uzyskane wyniki.
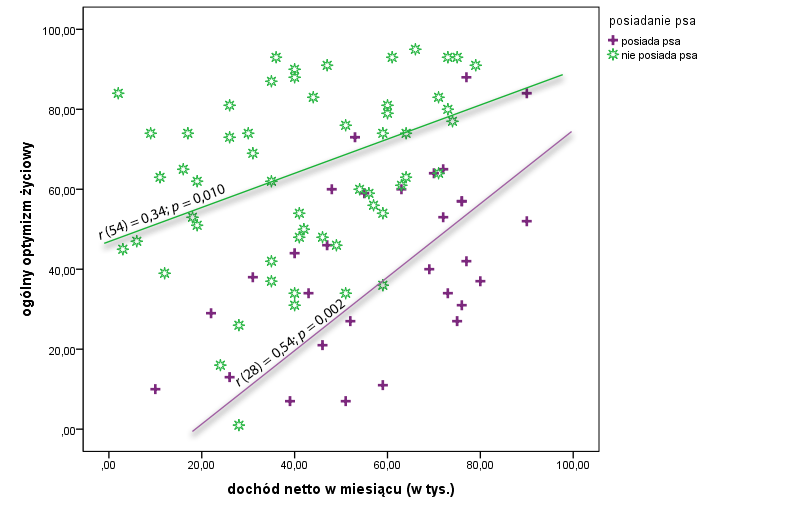
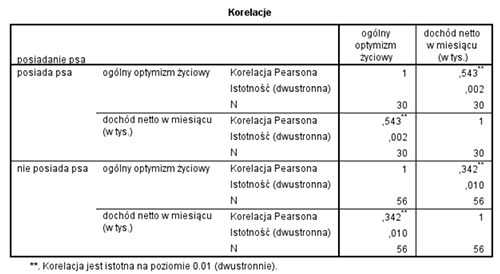
Jak widzisz nie tylko w jednej grupie, ale w obu jednocześnie, zachodzi istotny statystycznie związek między zarobkami a optymizmem. Co więcej, w jednej i drugiej grupie wartość wyliczonych współczynników korelacji r Pearsona wskazują na to, że związki mają umiarkowaną siłę. Współwystępowanie zarobków i optymizmu na charakter pozytywny (dodatni znak współczynnika korelacji), a co za tym idzie, im więcej zarabiamy tym większy jest nasz optymizm … lub im większy jest optymizm tym większe są nasze zarobki
Pamiętaj, że analiza korelacji nie uprawnia do wyciągania wniosków o tym co jest przyczyną a co skutkiem!
Jak to możliwe, że w całej grupie korelacja nie jest istotna, a za chwilę, także w całej grupie, ale podzielonej na dwie mniejsze grupki staje się ona istotna i jest w dodatku korelacją o średniej sile? Niestety odpowiedź może nie być dla Ciebie satysfakcjonująca. Po prostu tak jest. Podobnie jak w tym artykule, także tutaj sytuacją sprzyjającą występowaniu takiego zjawiska może być różnica między średnimi w zakresie jednej lub dwóch zmiennych, które ze sobą korelujemy. Teraz obserwujemy akurat zróżnicowanie tylko w zakresie ogólnego optymizmu życiowego (posiadacze psa są mniej optymistyczni niż osoby, które go nie posiadają). Jedna i druga grupa ma jednak bardzo zbliżony średni wyników miesięcznych dochodów. Tak jak podkreślamy to w tym wpisie, także tutaj pamiętaj koniecznie o tym, że różnice w średnich nie są przyczyną tego, że korelacja najpierw była nieistotna, a później stała się istotna w obu grupach oddzielnie. Jest to bardzo często sytuacja sprzyjająca. Jeśli porównasz sobie najpierw posiadaczy psa z osobami, które go nie posiadają pod względem optymizmu i dochodów (np. testem t Studenta dla prób niezależnych) to możesz po prostu przypuszczać, że skoro posiadanie psa różnicuje nasilenie obu tych zmiennych to jest szansa, że także “namiesza” nam ta zmienna w zakresie innych analiz, które przeprowadziliśmy lub mamy zamiar przeprowadzić.
PODKREŚLAM JEDNAK PONOWNIE – różnice w średnich między grupami, które rozbiły nam bazę danych na dwa podzbiory nie są przyczyną tego, że najpierw korelacja była nieistotna, a po podziale stała się istotna statystycznie w obu grupach.
Kolejny przykład ma na celu pokazanie, że nawet kiedy obie grupy mają niemal identyczne średnie w zakresie obu zmiennych ilościowych, które korelujemy, to i tak możemy zaobserwować “dziwne” zachowanie współczynnika korelacji.
Odwrotne związki w obu grupach. Wstęp do analizy moderacji.
Niniejszy, ostatni przykład ma na celu pokazanie jak inaczej może zachować się współczynnik korelacji gdy dokonamy podziału na podzbiory przed jego policzeniem. Cały czas jednak trzymamy się sytuacji, w której najpierw u ogółu badanych osób związek liniowy nie występuje, a po podziale na dwa podzbiory nagle robi się istotny statystycznie. Nawet w dwóch grupach jednocześnie! Nawet bardzo silny!
Tym razem chcemy skorelować ze sobą samoocenę moralności (czyli to, jak pozytywnie uczestnicy badania oceniają swoją moralność) oraz nasilenie zewnętrznego umiejscowienia poczucia kontroli (czyli skłonność do uznania, że mniej zależy od nas samych niż od zewnętrznych czynników takich jak pogoda lub “ślepy los”).
W wyniku przeprowadzonej analizy korelacji z wykorzystaniem współczynnika r Pearsona okazało się, że obie analizowane zmienne nie są ze sobą skorelowane – r(67) = -0,05; p = 0,690. Oznacza to, że samoocena moralności oraz nasilenie zewnętrznego umiejscowienia poczucia kontroli nie współwystępują ze sobą. Tak wygląda wykres rozrzutu oraz tabela z wynikami, którą otrzymamy w pakiecie SPSS.
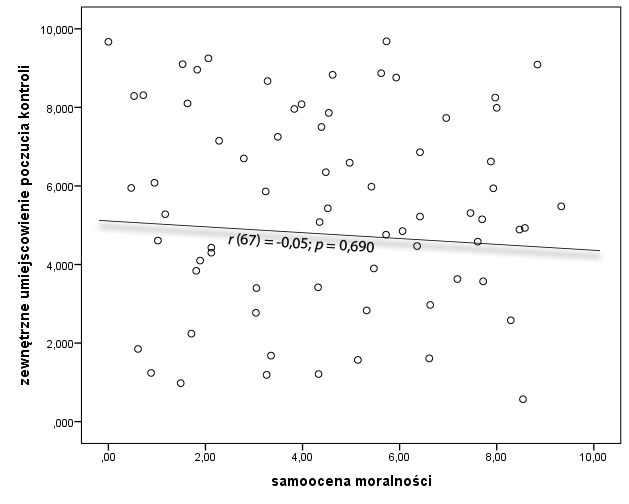

W naszej bazie danych znajduje się jednak jeszcze wiele różnych zmiennych, a w tym kontynent, z którego pochodzą badani – Europa lub Azja. Jako osoby o niezwykle wysokim poziomie ciekawości poznawczej dzielimy naszą bazę danych na podzbiory i jeszcze raz wykonujemy obliczenia. Dzięki temu dowiemy się czy brak związku liniowego między dwiema analizowanymi zmiennymi dostrzegalny jest oddzielnie w jednej jak i drugiej grupie. Oto wyniki.


Cóż się okazuje? Obserwujemy dwie, istotne statystycznie i całkiem silne korelacje, ale o odwrotnych znakach. Ujemny związek w Europie “zerował” się z dodatnim związkiem wśród mieszkańców Azji. Wzajemne “zwalczanie” się korelacji u ogółu badanych osób doprowadziło do tego, że właśnie bez podziału na dwie grupy korelacja nie występowała. Test wskazywał na zdecydowanie nieistotny statystycznie wynik i skłaniał nas do przyjęcia hipotezy zerowej. Okazuje się, że związek między samooceną moralności a nasileniem zewnętrznego umiejscowienia poczucia kontroli występuje, ale na jednym kontynencie w jednym kierunku, a na drugim kontynencie w innym kierunku. Przykład ten pokazuje, że obie grupy nie muszą wcale różnić się w zakresie dwóch mierzonych zmiennych ilościowych by dostrzegać “dziwne” wyniki analizy korelacji. Europejczycy mają bardzo zbliżone wyniki do Azjatów zarówno w przypadku jednej jak i drugiej zmiennej.
To co obserwujemy w tej chwili to klasyczny przykład efektu moderacji. O moderatorach i analizie moderacji będziemy mówili w innych postach i na pewno poświęcimy temu tematowi przynajmniej 2 tutoriale video. Teraz wspomnę tylko, że moderator to jakaś trzecia zmienna, która wpływa najczęściej na siłę lub kierunek związku między pierwszą a drugą zmienną. O efekcie moderacji możemy mówić np. gdy okaże się, że związek zachodzi w jednej grupie, a w drugiej nie zachodzi lub gdy mamy taką sytuację jak powyższa. W grupie Europejczyków korelacja ma znak ujemny natomiast w grupie Azjatów ma ona odwrotny, dodatni znak. Można uznać tym samym, że kontynent, z którego pochodzą badane osoby jest moderatorem relacji między samooceną moralności a wynikiem uzyskanym na skali zewnętrznego umiejscowienia poczucia kontroli. Zmienna będąca moderatorem wyjaśnia w jakich warunkach zaobserwować możemy poszukiwany efekt, a w jakich go nie zaobserwujemy lub będzie on odwrotny.
“Normalne” wyniki analizy korelacji w podziale na dwie grupy – podsumowanie
Zakładam, że do niedawna “dziwne” zachowanie się współczynników korelacji jest już teraz uznawane przez Was za zupełnie normalne. To nic dziwnego, i na pewno nie wynika to z popełnionego przez Was błędu, że korelacje u ogółu badanych osób są nieistotne statystycznie, a w podziale nagle stają się istotne na klasycznym poziomie p < 0,05. To standardowa sytuacja, która powinna Was cieszyć. Dlaczego? Dlatego, że dostarcza Wam świetnego materiału do napisania ostatniego rozdziału pracy dyplomowej czy też artykułu naukowego – dyskusji wyników i podsumowania. Dyskusja wyników jest dużo ciekawsza i pisze się ją znacznie łatwiej, gdy w wyniku przeprowadzonych analiz statystycznych uzyskujemy tak interesujące rezultaty. Polecam tym samym drążyć dane do granic możliwości. Jeśli macie czas, chęci i umiejętności to starajcie się zawsze wycisnąć z danych tyle ile się da. Powodzenia!
Tutaj znajdziesz pierwszą część artykułu – CZĘŚĆ 1



