Spis treści
Jak oszacować liczebność próby przy użyciu G*Power?
3 listopada 2023 | Autor: 
Wprowadzenie – czym jest i doczego służy G*Power?
G*Power to darmowe oprogramowanie statystyczne wykorzystywane przez badaczy i naukowców podczas planowania badań naukowych. Jego najczęściej wykorzystywaną funkcją jest szacowanie minimalnej liczebności próby wymaganej do przeprowadzenia określonego testu statystycznego, aby zwiększyć szansę wykrycia określonej siły efektu. Warto podkreślić, że jest to tylko jedna z kilku analiz, które można przeprowadzić w tym programie (pozostałe zostaną omówione w dalszej części tekstu), niemniej przez wielu badaczy G*Power traktowany jest wręcz jako program do szacowania liczebności próby.
Program G*Power został stworzony przez niemieckich badaczy, a sam projekt był finansowany przez niemiecki rząd. Ich zamiarem było stworzenie ogólnodostępnego narzędzia, które byłoby nie tylko precyzyjne, ale także proste w użyciu, tak aby mogło być wykorzystywane zarówno przez doświadczonych naukowców, jak i przez studentów czy początkujących badaczy. Jak najbardziej można uznać, że cel ten został osiągnięty – dzięki swojej precyzji i elastyczności, G*Power zdobył uznanie w społeczności naukowej i stał się jednym z najpopularniejszych narzędzi do analizy mocy testu statystycznego.
G*Power jako narzędzie do analizy mocy statystycznej
Centralnym pojęciem związanym z programem G*Power jest moc testu (inaczej znana jako moc statystyczna). Technicznie rzecz biorąc chodzi o prawdopodobieństwo, że test statystyczny prawidłowo odrzuci hipotezę zerową (H₀), gdy hipoteza alternatywna (H₁) jest prawdziwa . W uproszczeniu, można ją zatem traktować jako wielkość prawdopodobieństwa z jakim wynik testu statystycznego, który zastosujemy w naszym badaniu, wykaże istotność statystyczną, jeżeli badany związek lub różnica rzeczywiście istnieje.
Dbałość o właściwą moc statystyczną testu jest kluczowa dla otrzymania wiarygodnych wniosków opierających się na wynikach testów statystycznych . Ujmując sprawę prościej, chodzi o zapewnienie warunków, w którym test statystyczny wykaże wynik najbardziej adekwatny do rzeczywiście istniejącego w populacji. W pewnym sensie chodzi więc o „dostrojenie” danego testu w taki sposób, aby jego wynik był (uwzględniając statystyczne technikalia) rzetelny. Jeśli moc testu jest na odpowiednim poziomie, obliczona wartość p będzie prawidłowo odzwierciedlać realnie zmierzony efekt (którego bardziej bezpośrednim wskaźnikiem jest wartość wielkości efektu, np. współczynnik r Pearsona w analizie korelacji lub d Cohena w teście t Studenta).
Jeśli test statystyczny ma zbyt małą moc, może nie wykrywać efektu, który rzeczywiście jest znaczący (np. wynik nieistotny statystycznie przy umiarkowanej lub dużej wielkości efektu), lub ewentualne wykryte związki / różnice będą mało wiarygodne, gdyż będzie istniało małe prawdopodobieństwo replikacji wniosków. Z kolei zebranie próby zapewniającej zbyt dużą moc testu, spowoduje wykrycie wielu istotnych statystycznie wyników, ale o niskiej realnej wartości naukowej (np. korelacje rzędu r = 0,12, które często interpretuje się jako „brak znaczącej korelacji między zmiennymi” lub „brak efektu”).
Warto pamiętać o tym, że moc statystyczna nie jest stałą cechą danego testu statystycznego. Dany test charakteryzuje określona moc w danej analizie, ponieważ zależy ona od kilku czynników, które mogą mieć różną wielkość w różnych badaniach.
Moc testu statystycznego to prawdopodobieństwo, że test statystyczny prawidłowo odrzuci hipotezę zerową (H₀), gdy hipoteza alternatywna (H₁) jest prawdziwa. W uproszczeniu, można ją zatem traktować jako wielkość prawdopodobieństwa z jakim wynik testu statystycznego, wykaże istotność statystyczną, jeżeli badany związek lub różnica rzeczywiście istnieje.
Jakie konkretnie czynniki wpływają na moc danego testu? W większości testów statystycznych chodzi o:
1. Wariant testu statystycznego: Test jednostronny (stosowany przy hipotezie kierunkowej) ma zazwyczaj większą moc statystyczną w porównaniu do testu dwustronnego (hipoteza bezkierunkowa), ponieważ całe prawdopodobieństwo błędu typu I (α) jest skoncentrowane po jednej stronie rozkładu prawdopodobieństwa. Test dwustronny jest bardziej konserwatywny i częściej stosowany w badaniach naukowych, gdyż pozwala badać efekty w obu kierunkach.
2. Wielkość efektu: Jest to miara wielkości różnicy lub związku, który badacz próbuje wykryć. Rozmiar efektu może być mały, średni lub duży. Większa siła efektu zwiększa moc statystyczną , ponieważ wykrycie istotnych statystycznie różnic staje się łatwiejsze.
3. Poziom istotności alfa (α): To prawdopodobieństwo odrzucenia prawdziwej hipotezy zerowej (błąd typu I). Standardowo ustawiany jest na 0,05. Niższy poziom istotności (mniejsza wartość α) wiąże się z niższą mocą statystyczną , ponieważ oznacza mniejsze ryzyko odrzucenia prawdziwej hipotezy zerowej. Upraszczając sprawę – im mniejsza wartość α, tym trudniej jest uzyskać istotny statystycznie wynik dla danego efektu, ponieważ na podstawie wartości α określa się próg dla interpretacji wartości p.
4. Liczebność próby: Większa liczebność próby zwykle prowadzi do wyższej mocy statystycznej , dzięki czemu łatwiej jest wykryć efekty, które są rzeczywiście obecne.
Poza powyższymi czynnikami, w przypadku niektórych testów statystycznych na ich moc statystyczną wpływają też inne czynniki, przykładowo: liczba predyktorów w analizie regresji liniowej, liczba porównywanych grup w teście ANOVA. Do niektórych z nich nawiążemy w późniejszej części tekstu, a szczegółowe informacje w tym zakresie można znaleźć w oficjalnym podręczniku do G*Power.
G*Power jako narzędzie do analizy… kilku innych wielkości
Jak pokazaliśmy wyżej, moc testu statystycznego zależy od kilku czynników. W uproszczeniu, możemy myśleć o mocy statystycznej jako o wyniku pewnego równania matematycznego. Te mają to do siebie, że można je przekształcać. Oznacza to, że skoro na podstawie kilku wartości można obliczyć moc statystyczną, to przekształcając wzór, możemy obliczyć każdą z tych pozostałych wartości. Wtedy wartość mocy statystycznej znajdzie się po prawej stronie równania, jako element wzoru.
Powyższe zależności powodują, że G*Power pozwala na obliczenie kilku różnych wartości związanych z mocą statystyczną. Konkretnie, w programie do dyspozycji mamy jedną z pięciu analiz:
1. Analiza a priori: Obliczenie wymaganej liczebności próby (próbę o jakiej liczebności musimy zbadać, przy założeniu określonej mocy testu, wielkości efektu oraz wartości α).
2. Analiza warunkowa (compromise): Obliczenie domniemanej mocy i wartości alfa (jaka będzie planowana moc testu oraz zakładana wartość α przy określonej sile efektu, wielkości próby oraz stosunku wartości α do β, tj. stosunku wartości błędów pierwszego i drugiego rodzaju).
3. Analiza kryterialna (criterion): Obliczenie wymaganej wartości α (jaką wartość α powinniśmy przyjąć przy założeniu określonej mocy testu, wielkości efektu i liczebności próby).
4. Analiza post hoc: Osiągnięta moc (jaką uzyskaliśmy moc statystyczną dla liczebności próby, którą zbadaliśmy, uzyskanej w analizie wielkości efektu i przyjętej dla badania wartości α).
5. Analiza czułości (sensitivity): Obliczenie wymaganej wielkości efektu (jaką wielkością efektu w populacji powinno charakteryzować dane zjawisko, aby można było je wykryć danym testem, przy założeniu określonej mocy testu, wartości α oraz liczebności próby).
Jeśli powyższe zagadnienia związane z różnymi możliwościami analiz, jakie można wykonać w G*Power, są dla Ciebie zbyt skomplikowane – nie przejmuj się. Ten wpis koncentruje się na zagadnieniu oszacowania wymaganej liczebności próby i nie musisz znać tych wszystkich szczegółów, aby w tym celu korzystać z G*Power. Warto jednak znać szerszy kontekst i wiedzieć, że program ten posiada więcej funkcji, które mogą być dla Ciebie przydatne w przyszłości.
Choć program G*Power jest stosowany najczęściej do szacowania liczebności próby, umożliwia on wykonanie kilku innych analiz związanych z mocą statystyczną, m.in. oszacowania osiągniętej mocy testu w danym badaniu, wymaganej wartości alfa (α) lub wymaganej wielkości efektu.
G*Power jako narzędzie do szacowania minimalnej liczebności próby
Wiemy już, że badanie naukowe nakierowane na weryfikację hipotez statystycznych powinno opierać się o „balans” pewnych właściwości związanych z działaniem danego testu. Tylko w ten sposób będzie miał on właściwą moc, i co za tym idzie, jego wynik będzie wiarygodny w interpretacji. Wiemy też, że moc statystyczna jest wypadkową kilku czynników, którymi powinniśmy manipulować tak, aby uzyskać określoną jej wartość.
W praktyce jednak zwykle manipuluje się tylko jedną z wartości związanych z mocą statystyczną – liczebnością próby . Jest tak, ponieważ pozostałe z tych wartości, rzadko kiedy podlegają naszej realnej kontroli. Dlaczego? Przyjrzyjmy się poszczególnym wartościom:
1. Wariant testu statystycznego: Wybór testu dwustronnego vs jednostronnego jest arbitralny, często domyślnie wybiera się dwustronny; jeśli natomiast wykorzystujemy test jednostronny, to jest to (o ile nie stosujemy nadużyć metodologicznych) efektem rodzaju postawionej hipotezy (jednostronnej).
2. Moc testu statystycznego (1-β): Wartość samej mocy testu statystycznego również przyjmuje się na określonym, z góry założonym poziomie. Zwykle jest to wartość między 0,80 a 0,95 , co oznacza, że istnieje od 5% do 20% (β) prawdopodobieństwa na to, że rzeczywiście istniejący efekt nie zostanie wykryty (technicznie rzecz biorąc – chodzi o odrzucenie prawdziwej hipotezy alternatywnej na rzecz fałszywej hipotezy zerowej). Dobór mocy statystycznej powinien uwzględniać kontekst badania i skutki błędu drugiego rodzaju (nieodrzucenie fałszywej hipotezy zerowej).
3. Wielkość efektu: Powinniśmy ją oszacować na podstawie literatury. Jeśli efekt w innych badaniach czy metaanalizie jest np. silny, to taki też powinniśmy określić w parametrach G*Power. Jeśli nie wiemy jaka jest wartość efektu w populacji, zakładamy zwykle umiarkowaną jej wielkość . Niemniej, wybór ten powinien być uzasadniony i nie powinien zależeć od preferencji badacza.
4. Poziom istotności alfa (α): Standardowo jest ustawiany na poziomie 0,05 ; rzadko kiedy wartość tę poddaje się manipulacji, a jeśli tak, to w uzasadnionych przypadkach (np. w przypadkach klinicznych lub danych biologicznych, kiedy wyniki badań mogą mieć poważniejsze konsekwencje np. dla życia ludzkiego).
5. Inne parametry: Podobnie sprawa wygląda z innymi parametrami związanymi z mocą statystyczną, takimi jak liczba predyktorów (w przypadku wykonywania analizy regresji) czy liczba porównywanych grup (w przypadku testu ANOVA) – są one z góry określone, w tym sensie, że zależą od rodzaju wykonywanej analizy.
Biorąc pod uwagę powyższe czynniki, okazuje się, że jedynym który możemy „dowolnie” manipulować, pozostaje liczebność próby. Jest to tym samym powód, dlaczego w praktyce tak wielu badaczy traktuje G*Power jako kalkulator do obliczania właśnie tej wartości. W takiej sytuacji, do programu wprowadzamy określone parametry testu, do których następnie dobierana jest określona liczebność próby, jaką musimy zbadać.
Warto też wspomnieć, że różne testy statystyczne wymagają liczebności próby o różnej wielkości . Przykładowo, analiza korelacji dobrze „zadziała” już przy próbie liczącej 70-140 osób (w zależności od przyjętej siły efektu i mocy testu), podczas gdy złożone modele regresji lub warianty ANOVA mogą wymagać np. dwukrotnie czy trzykrotnie większej liczby obserwacji dla efektu o tej samej wielkości. Rodzi to dylemat w momencie, w którym w ramach jednego badania wykorzystuje się różne metody statystyczne. W takiej sytuacji zwykle szacuje się wielkość próby dla wszystkich metod statystycznych z osobna i jako docelową przyjmuje się tę w odniesieniu do metody, dla której powinna być ona największa. Takie rozwiązanie co prawda skutkuje zawyżeniem mocy testu dla metod, które wymagają mniejszej liczby obserwacji, ale z drugiej strony pozwala to uniknąć zbyt niskiej mocy dla metod o największych wymaganiach w tym zakresie.
W tym momencie kończymy rozważania teoretyczne dotyczące zagadnień związanych z mocą testu i szacowaniem liczebności próby. W kolejnych fragmentach tekstu przedstawione zostaną praktyczne instrukcje dotyczące korzystania z G*Power.
Moc testu statystycznego zależy od kilku czynników (m.in. wielkości efektu i poziomu istotności alfa). W praktyce jednak, badacz może dowolnie manipulowa jedynie liczebnością próby. Dlatego też odpowiednie jej oszacowanie jest tak istotne dla uzyskania odpowiedniej mocy testu.
Jak korzystać z G*Power do szacowania liczebności próby?
1. Pobieranie i instalacja programu G*Power
G*Power jest darmowy i jego najnowszą wersję można pobrać z oficjalnej strony programu. Istnieje wersja programu na systemy Windows oraz macOS. Instalacja programu jest prosta i intuicyjna, w razie potrzeby pod powyższym linkiem można też pobrać instrukcję obsługi programu. Całość pokazano w poniższym screenie:
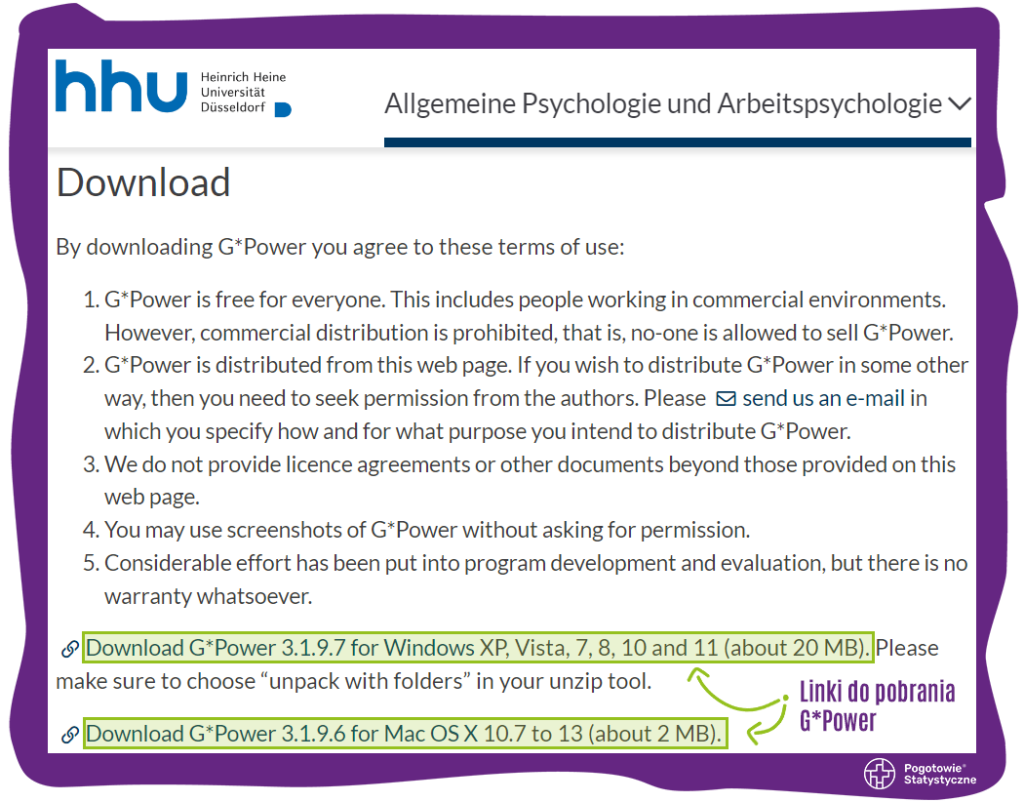
Źródło: https://www.psychologie.hhu.de/arbeitsgruppen/allgemeine-psychologie-und-arbeitspsychologie/gpower (dostęp: 03.03.2026 r.)
2. Zapoznanie się z interfejsem programu
G*Power ma przejrzysty i intuicyjny interfejs, składający się z różnych pól, w których użytkownik może określić rodzaj analizy jaką chce przeprowadzić oraz jej parametry.
Interfejs G*Power (w wersji 3.1) wygląda w sposób pokazany na poniższym screenie. Na zrzucie ekranu opisano poszczególne pola:
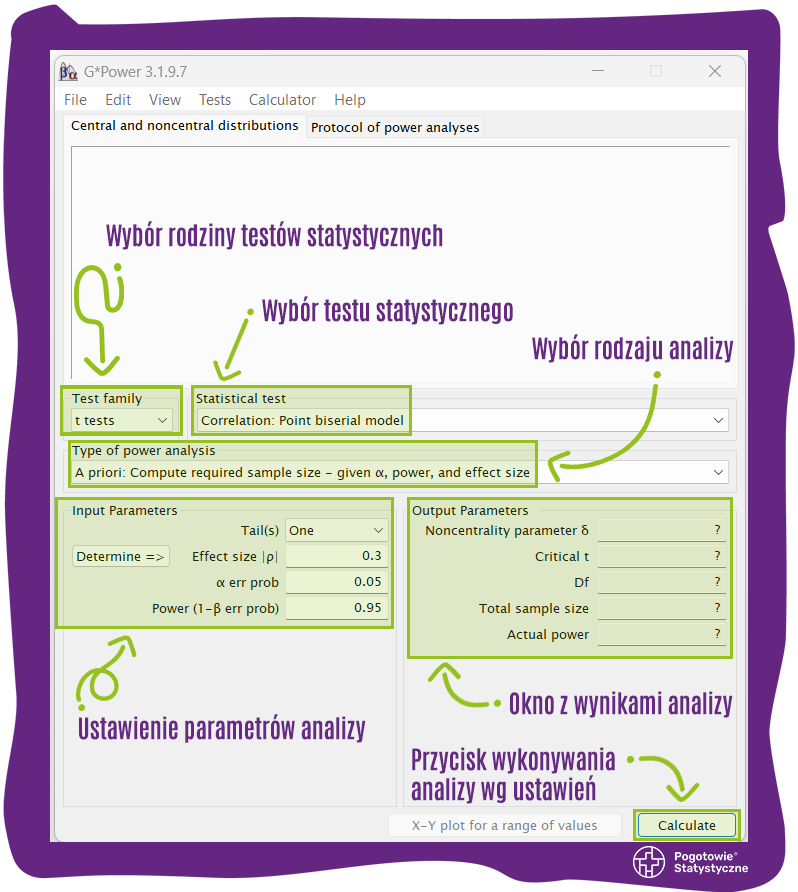
3. Ustawienie opcji szacowania liczebności próby
Jak opisano wcześniej, G*Power pozwala na obliczenie pięciu różnych parametrów związanych z mocą statystyczną: wymaganą liczebność próby; domniemaną moc i wartość α; wymaganą wartość α; osiągniętą moc statystyczną; wymaganą wielkość efektu.
Aby obliczyć wymaganą liczebność próby, należy w menu Type of power analysis wybrać opcję A priori: Compute required sample size – given α, power and effect size. Pokazano to na poniższym screenie:
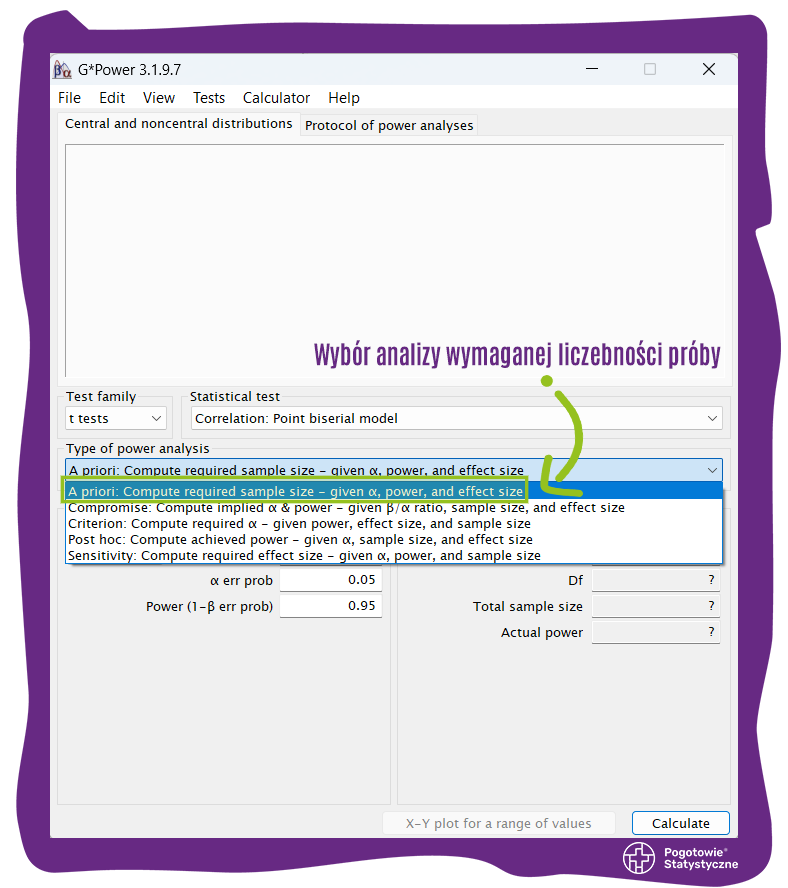
4. Wybór testu statystycznego
Kolejnym krokiem jest wybór testu statystycznego, dla którego chcemy dokonać oszacowania liczebności próby. Dokonujemy go poprzez ustawienie dwóch osobnych opcji:
- Rodzina testów: tu wybieramy rodzinę testów statystycznych spośród pięciu opcji: testy dokładne (Exact), F, t, χ2, Z.
- Test statystyczny: tu wybieramy konkretny test statystyczny z rodziny testów wskazanych powyżej. W skład danej rodziny testów wchodzi od kilku do kilkunastu różnych testów.
Oto kilka przykładów ustawień, które należy wybrać dla popularnych testów statystycznych:
Analiza korelacji Pearsona:
– Test family: Exact
– Statistical test: Correlation: Bivariate normal model
Test t Studenta dla prób niezależnych:
– Test family: t tests
– Statistical test: Means: Difference between two independent means (two groups)
Jednoczynnikowa ANOVA dla prób niezależnych:
– Test family: F tests
– Statistical test: ANOVA: Fixed effects, omnibus, one-way
Analiza regresji liniowej:
– Test family: F tests
– Statistical test: Linear multiple regression: Fixed model, R2 deviation from zero
Przykładowe wyniki szacowania liczebności próby dla tych testów zostaną przedstawione w kolejnych fragmentów tekstu.
5. Wprowadzenie parametrów badania
Aby oszacować liczebność próby, należy wprowadzić kilka parametrów. Dla większości testów jest to:
- Poziom Istotności (α): zwykle 0,05
- Moc Statystyczna (1 – β): zwykle 0,80, 0,90 lub 0,95
- Wielkość Efektu: zwykle wyświetlana przez program po najechaniu kursorem na „effect size”
Parametry te zostały opisane dokładniej wcześniej.
Ponadto, dla niektórych testów statystycznych wprowadza się również inne wartości, takie jak liczba porównywanych grup w ANOVA lub ilość predyktorów w analizie regresji liniowej.
6. Szczegółowe obliczenia i interpretacja wyników
Po wprowadzeniu parametrów, G*Power automatycznie oblicza sugerowaną liczebność próby (po kliknięciu opcji calculate po wprowadzeniu zmian). Wyniki można analizować za pomocą dodatkowych funkcji programu, takich jak wykresy mocy oraz opcji zawierających szczegółowe informacje. Ważne jest, aby interpretować wyniki z uwzględnieniem kontekstu badania oraz dostępnych zasobów.
Poniżej przedstawiamy przykładowe wyniki szacowania liczebności próby dla różnych wariantów użycia kilku popularnych testów statystycznych. Uwzględniają one ustawienie wartości mocy testu na wartość 0,80, jednakże, przedstawiono również wynik analogicznych analiz, ale przy założeniu mocy testu wynoszącej 0,95. Należy podkreślić, że są to tylko przykłady i przy wykonywaniu własnych analiz trzeba zadbać o właściwe ustawienie jej parametrów.
(1) Test t Studenta dla prób niezależnych: 128 obserwacji przy założeniu: testu dwustronnego, umiarkowanej wielkości efektu w populacji (d = 0,5), wartości α = 0,05, mocy testu = 0,80, równej proporcji liczebności obu podgrup (po 64 obserwacje na grupę). Zrzut ekranu ustawień i wyniku tej analizy przedstawiono poniżej:
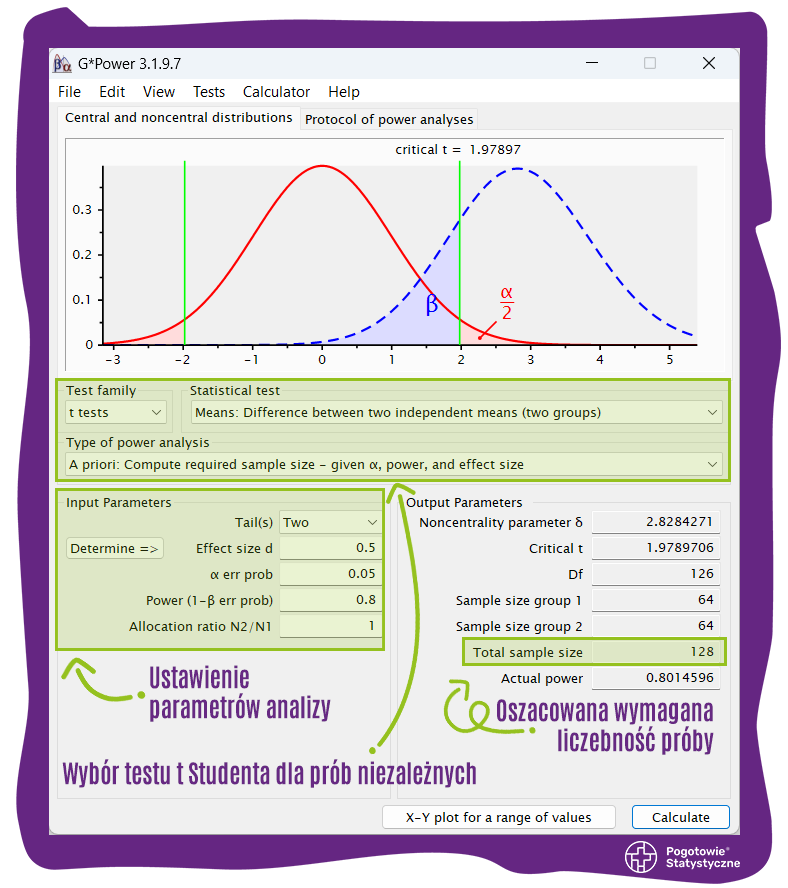
Wynik analogicznej analizy, ale dla mocy testu wynoszącej 0,95 wynosi: 210 obserwacji (po 105 na grupę).
(2) ANOVA dla prób niezależnych: 159 obserwacji, przy założeniu: porównywania trzech grup, umiarkowanej wielkości efektu w populacji (f = 0,25), wartości α = 0,05, mocy testu = 0,80. Zrzut ekranu ustawień i wyniku tej analizy przedstawiono poniżej:
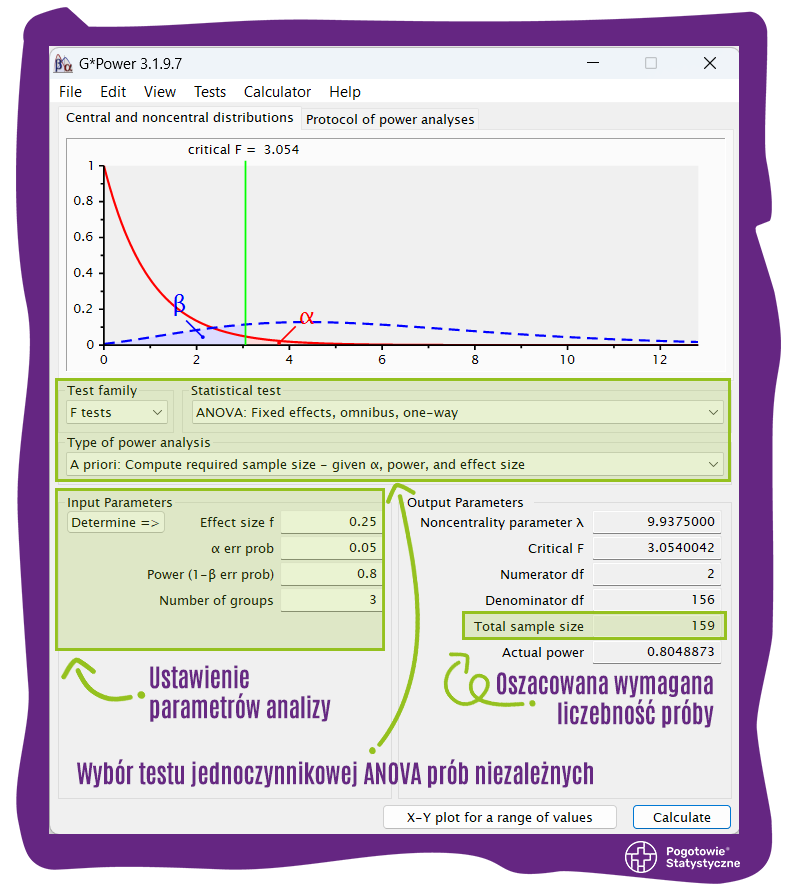
Wynik analogicznej analizy, ale dla mocy testu wynoszącej 0,95 wynosi: 252 obserwacje.
(3) Analiza korelacji Pearsona: 84 obserwacje, przy założeniu: testu dwustronnego, umiarkowanej wielkości efektu w populacji (ρ = 0,3), wartości α = 0,05, mocy testu = 0,80. Zrzut ekranu ustawień i wyniku tej analizy przedstawiono poniżej:
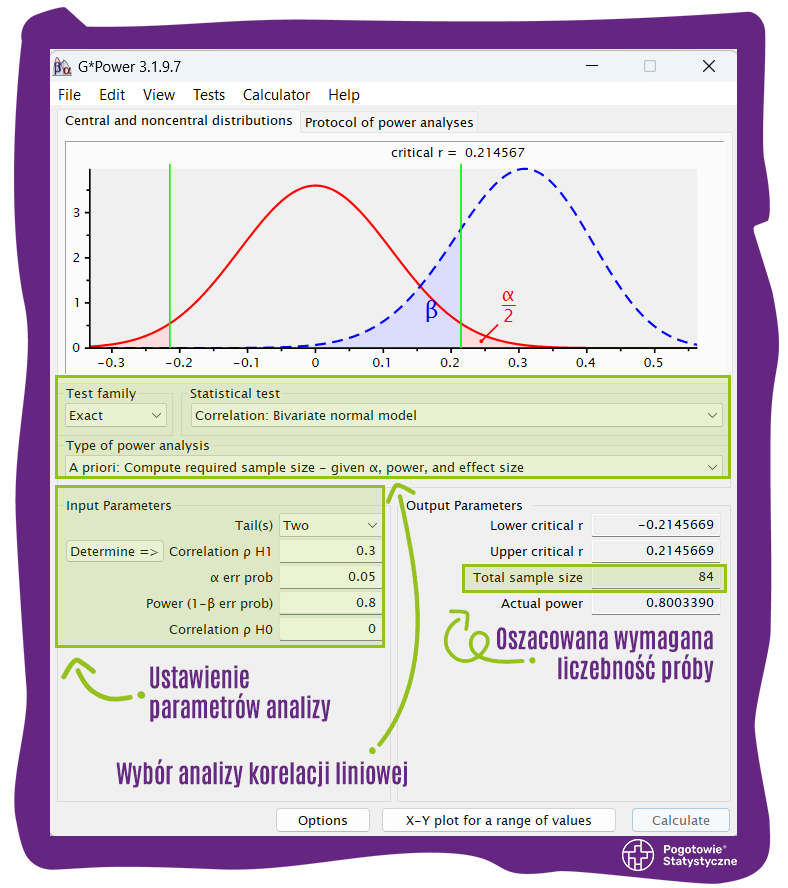
Wynik analogicznej analizy, ale dla mocy testu wynoszącej 0,95 wynosi: 138 obserwacji.
(4) Analiza regresji liniowej: 85 obserwacji, przy założeniu: umiarkowanej wielkości efektu w populacji (f2 = 0,15), wartości α = 0,05, mocy testu = 0,80, czterech predyktorów. Zrzut ekranu ustawień i wyniku tej analizy przedstawiono poniżej:
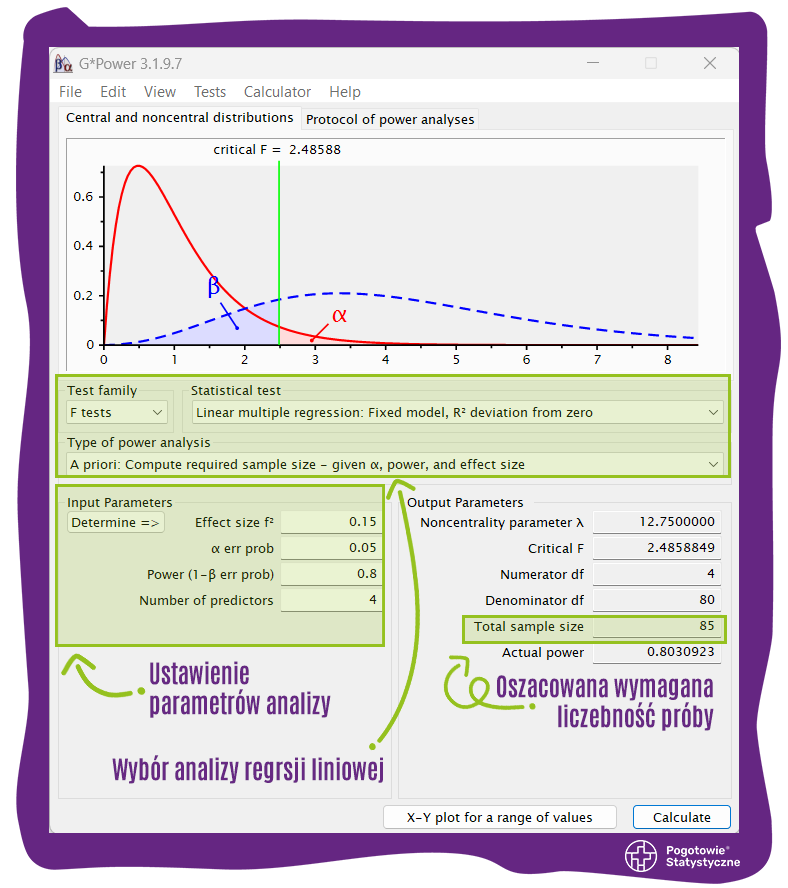
Wynik analogicznej analizy, ale dla mocy testu wynoszącej 0,95 wynosi: 129 obserwacji.
Podsumowanie wyżej opisanych wyników zaprezentowano w poniższej tabeli.
| Test statystyczny | Oszacowana liczebność próby | |
| moc (1 – β) = 0,80 | moc (1 – β) = 0,95 | |
| Test t Studenta dla prób niezależnych, przy założeniu: testu dwustronnego, umiarkowanej wielkości efektu w populacji (d = 0,5), wartości α = 0,05, równej proporcji liczebności obu grup. | 128 | 210 |
| ANOVA dla prób niezależnych, przy założeniu: porównywania trzech grup, umiarkowanej wielkości efektu w populacji (f = 0,25), wartości α = 0,05. | 159 | 252 |
| Analiza korelacji Pearsona, przy założeniu: testu dwustronnego, umiarkowanej wielkości efektu w populacji (ρ = 0,3), wartości α = 0,05. | 84 | 138 |
| Analiza regresji liniowej, przy założeniu: umiarkowanej wielkości efektu w populacji (f2 = 0,15), wartości α = 0,05, czterech predyktorów. | 85 | 129 |
Jak można zaobserwować, wielkość próby znacząco wzrasta gdy założymy wyższą moc testu , jest to jednak korzystne dla badacza, gdyż redukuje prawdopodobieństwo przyjęcia fałszywej hipotezy zerowej (brak efektu) z 20% do zaledwie 5%. Oznacza to, że stwierdzenie braku efektu, który istnieje w populacji może zostać popełnione nie w jednym na pięć badań, a w jednym na dwadzieścia badań.
7. Praktyczne wskazówki dotyczące wykorzystania programu
Dokładność Parametrów: Im dokładniejsze są parametry wprowadzone do programu, tym bardziej precyzyjne są obliczenia liczebności próby . Przykładowo, jeśli mamy dane z wcześniejszych badań albo innych publikacji, to możemy dokładniej oszacować liczebność próby, aby zwiększyć prawdopodobieństwo replikacji.
Analizy Wrażliwości: Funkcje analizy wrażliwości w G*Power pozwalają badać, jak różne wartości parametrów wpływają na wyniki, co jest przydatne do oceny odporności (ang. robustness) planowanego badania. Przykładowo, sprawdzając jak zmienia się liczebność próby w zależności od różnych parametrów możemy „manipulować” jej wielkością tak, aby uzyskać jak najbardziej wiarygodne wyniki.
Graficzna Reprezentacja Wyników: Program oferuje różne opcje graficzne, które pomagają zrozumieć, jak zmiany w parametrach wpływają na wymaganą liczebność próby.
8. Uwzględnienie straty i niekompletności danych
Należy pamiętać o potencjalnej stracie ilości obserwacji oraz o brakujących danych podczas prowadzenia badania. Planując liczebność próby, warto z góry założyć pewien procent straty (zwykle 10-20%, a w badaniach podłużnych nawet do 50%), aby wyniki były wiarygodne mimo ewentualnych problemów w tej kwestii.
9. Zaawansowane opcje programu
G*Power umożliwia bardziej zaawansowane analizy, takie jak analizy post-hoc oraz symulacje Monte Carlo. Dzięki temu badacze mogą dokładniej planować swoje badania, szacując liczebność próby w różnych scenariuszach i dla różnych modeli statystycznych.
Podsumowanie
G*Power jest niezastąpionym narzędziem dla badaczy w różnych dziedzinach nauki. Pozwala on szacować różne parametry związane z mocą statystyczną, choć zwykle jest wykorzystywany jako narzędzie do określania, jaka liczebność próby jest wymagana dla uzyskania wiarygodnych wyników badania.Interfejs programu jest prosty i przejrzysty, dzięki czemu za pomocą kilku kliknięć możemy oszacować wymaganą liczebność próby dla wielu popularnych testów statystycznych.
W tym artykule przedstawiliśmy podstawową wiedzę związaną z mocą statystyczną i szacowaniem liczebności próby, a także instrukcje dotyczące korzystania z G*Power wraz z przykładami dla kilku popularnych testów statystycznych. Odpowiednie korzystanie z programu, poparte solidną wiedzą statystyczną, może znacząco przyczynić się do poprawy jakości przeprowadzanych badań naukowych.
Literatura:
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Hillsdale, NJ: Erlbaum.
Faul, F., Erdfelder, E., Lang, A., Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175-191. doi:10.3758/bf03193146
Faul, F., Erdfelder, E., Buchner, A., Lang, A. (2009). Statistical power analysesusing G*Power 3.1: Tests for correlation and regression analyses. Behavior Research Methods, 41(4), 1149-1160. doi:10.3758/brm.41.4.1149
https://www.psychologie.hhu.de/arbeitsgruppen/allgemeine-psychologie-und-arbeitspsychologie/gpower (dostęp 27.10.2023 r.)

