Słownik
R-kwadrat (korelacja wielokrotna)
Współczynnik R-kwadrat (R2) – rodzaj współczynnika determinacji (czyli wskaźnika, który mierzy jakość dokonywanej prognozy), który pozwala na ocenę jakości dopasowania testowanego modelu do danych. Zwykle wykorzystywany jest w analizie regresji liniowej, choć obliczany jest również w przypadku analizy wariancji (ANOVA).
Współczynnik determinacji R2 określa jak duża część zmienności zmiennej zależnej (wyjaśnianej) jest wyjaśniana przez zmienne niezależne (wyjaśniające) w modelu regresji. Przyjmuje on wartości od 0 do 1, co w prosty sposób można zamienić na wartości procentowe (0 – 100%), np. R2 = 0,15 = 15%.
Wykonując analizę statystyczną w danym pakiecie statystycznym, np. w SPSS, często w praktyce obliczane są dwa rodzaje wartości tego współczynnika, które określane są jako:
1. Współczynnik R2 – stosujemy go, kiedy mamy tylko jeden predyktor w modelu (czyli w praktyce bardzo rzadko).
2. Skorygowany współczynnik R2 – stosowany w modelach regresji wielorakiej, w których predyktorów jest więcej niż jeden.
Różnica między nimi polega na tym, że “zwykła” wartość R2 zawsze wzrasta po dodaniu kolejnych zmiennych do modelu, niezależnie od tego, czy prowadzą do poprawy jego jakości, co wiąże się z ryzykiem przeszacowania jego dopasowania. Z kolei skorygowana wersja współczynnika R2 uwzględnia liczbę zmiennych w modelu i dzięki temu pozwala na bardziej ostrożną ocenę dopasowania.
W celu rozważenia prostego przykładu, wyobraźmy sobie badanie, w którym chcemy wyjaśnić poziom satysfakcji pracowników (zmienna zależna), na podstawie wysokości ich wypłaty i poziomu stresu (predyktory). Na rysunku 1 przedstawiono graf, który odnosi się do potencjalnej relacji między tymi zmiennymi.
Rysunek 1
Przykładowa zależność między predyktorami a zmienną zależną w analizie regresji
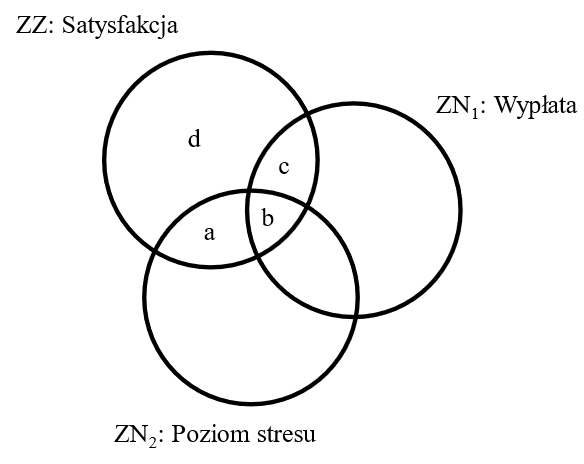
Adnotacja. ZZ – zmienna zależna, ZN – zmienna niezależna.
Poszczególne oznaczenia literowe można wyjaśnić następująco:
a = część satysfakcji, którą wyjaśnia korelacja (semicząstkowa) z poziomem stresu.
b = część satysfakcji, którą wyjaśnia zarówno poziom stresu, jak i wypłata (współliniowość).
c = część satysfakcji, którą wyjaśnia korelacja (semicząstkowa) z wypłatą.
d = niewyjaśniona część satysfakcji, która koreluje z innymi, niekontrolowanymi w modelu zmiennymi.
Przypuśćmy, że w naszym przykładzie uzyskaliśmy wartość współczynnika R2 = 0,37 (jest to suma: a+b+c). Oznaczałoby to, że model ten (oba wprowadzone predyktory) wyjaśnia 37% wariancji wyników dotyczących satysfakcji pracownika. Z jednej strony to stosunkowo dużo, ale z drugiej nadal istnieje jeszcze 63% wariancji która nie była wyjaśniona przez zmienne uwzględnione w modelu.
Wartość R2 można nie tylko określać dla całego modelu, zawierającego wszystkie predyktory. Istnieje typ analizy regresji, tzw. hierarchiczny model regresji, w którym możemy wprowadzać określone kombinacje predyktorów w kolejnych etapach (blokach) i porównywać uzyskane wartości R2. Podczas takiej analizy mogłoby się okazać przykładowo, że zestaw zmiennych wprowadzony w pierwszym bloku wyjaśnia 20% wariancji, a zestaw kolejnych predyktorów dodany do modelu podnosi tę wartość do 37% (wzrost o 17%). W ten sposób można określić w jakim stopniu zmienia się jakość modelu w zależności od konfiguracji predyktorów.
Choć współczynnik R2 jest bardzo przydatny do oceny jakości modelu regresji, ma on pewne ograniczenia:
1. Przyczynowość – nawet bardzo wysoki współczynnik R2 nie wskazuje na przyczynowy charakter relacji między zmiennymi w modelu, tzn. nie jest dowodem na to że to zmienna niezależna wpływa na zmienną zależną.
2. Jakość modelu – współczynnik R2 pozwala ocenić jedynie dopasowanie do danych. To jednak nie jest jednoznaczne z jakością i precyzją predykcji, czego ciekawymi przykładami jest tzw. kwartet Anscombe’a.
3. Udział zmiennych – w przypadku niektórych analiz wartość R2 nie odnosi się do do dopasowania wszystkich zmiennych testowanych w modelu, ponieważ część z nim mogła zostać wykluczona z modelu.
4. Wartości odstające – w przypadku występowania obserwacji odstających wartość współczynnika R2 może być zniekształcona, przez co nie będzie odzwierciedlać rzeczywistej jakości modelu. Szczególnie w przypadku wysokiego współczynnika R2 warto przejrzeć dane pod kątem występowania outlierów.
Podsumowując, współczynnik R-kwadrat jest przydatnym narzędziem do oceny dopasowania modelu regresji liniowej do danych, a także porównywania modeli regresji między sobą. Warto jednak pamiętać o jego ograniczeniach – każda analiza statystyczna jest narzędziem w rękach badacza i powinna być stosowana adekwatnie do okoliczności oraz w oparciu o konkretne założenia statystyczne. Próba uzyskania wysokiej wartości R2 za wszelką cenę może prowadzić do nadużyć, np. tworzenia modeli regresji z dużą ilością predyktorów, bez konkretnego uzasadnienia teoretycznego.
Warto pamiętać, że wartość R2 to tylko jedna z istotnych wartości związanych z wynikami analizy regresji liniowej. Poza nią, zwykle raportujemy również m.in. współczynniki regresji (standaryzowany i niestandaryzowany) oraz wynik analizy wariancji oceniającej ogólne dopasowanie modelu. Przykład raportowania wyników analizy regresji w oparciu o standard APA 7 można znaleźć w tym miejscu.


